
или как я написал свою хранилку
Виталий Филиппов
Vitastor
- vitastor.io
- Быстрая распределённая SDS 🚀
- Latency от ~0.1 мс
- При этом архитектурно схожая с Ceph RBD
- Блочная (диски ВМ / контейнеров)
- Симметричная распределённая
- Ø SPOF
- Нативный QEMU-драйвер
- Простая (без DPDK и т.п.)
- Моя личная разработка
Что такое производительность?
- Q=1
- Лучшая возможная задержка
- Не каждое приложение может Q=128 (СУБД...)
- Исторически закрывалась кэшами RAID
- 4k запись на SSD — 0.04 мс
- В Ceph от ~ 1 мс — 2400 % overhead !
- Внутренние SDS облаков – ± аналогично
Как изнасиловать сетевой диск
Методика:
- Взять SSD диск
- Заполнить
- Пробить кэш
- fio -name=test
-ioengine=libaio
-direct=1
-filename=/dev/sd..
-bs=4k
-iodepth=1 - -rw=randwrite
-fsync=1 - -rw=randread

iops: больше – лучше
Apples to Apples
Методика:
- Взять SSD диск
- Заполнить
- Пробить кэш
- fio -name=test
-ioengine=libaio
-direct=1
-filename=/dev/sd..
-bs=4k
-iodepth=1 - -rw=randwrite
-fsync=1 - -rw=randread

iops: больше – лучше
Всё же будем насиловать всех
Методика:
- Взять SSD диск
- Заполнить
- Пробить кэш
- fio -name=test
-ioengine=libaio
-direct=1
-filename=/dev/sd..
-bs=4k
-iodepth=1 - -rw=randwrite
-fsync=1 - -rw=randread
iops: больше – лучше
Это не просто хранилка
Это, мать твою, высший сорт! (c)
С чего всё началось
У меня было 4 диска: 2+2+3+3 ТБ

Thin RAID 5
- Диски разных размеров собрать в RAID 5
- Не терять место
- Не делать resync
- Можно?
Диск 1 111422333
Диск 2 114222333
Диск 3 111222
Диск 4 333214 - Но так никто не умеет (до сих пор)
- ...кроме программных СХД
Программная СХД (SDS)
ПО, объединяющее обычные серверы с обычными дисками в единое масштабируемое отказоустойчивое хранилище, имеющее расширенные функции
Кто использует SDS?

И все-все-все, не зря в цефочате 1600+ человек
Да неужели нет хороших SDS?

Нечего надеть

Нечего надеть
Существующие хранилки...
- Либо теряют данные
- Либо медленные
- Либо платные
- Либо комбинации 1, 2, 3


Каг таг
 *FS только притворяются, что делают ФС
*FS только притворяются, что делают ФС vSAN жив, S2D на SMB, но вроде тоже
vSAN жив, S2D на SMB, но вроде тоже Weka.io, OpenEBS, StorageOS, Intel DAOS
Weka.io, OpenEBS, StorageOS, Intel DAOS
↑ неведомые зверюшки- Да, Minio тоже может терять данные
- Мне приснился QEMU-драйвер Storpool
- Есть доверие к Ceph, Seaweed, Linstor
А в чём проблема?
RAID по сети
Алгоритмы? Какие алгоритмы?
Пишем в 3 места, всё просто и быстро
Сюрпризы
- Без fsync данные до диска не доедут
- Запись на диск не атомарна
- RAID 5 WRITE HOLE
- Где-то нужно хранить метаданные
- Проблемы ФС поверх ФС
- Вы знали?
- А авторы MooseFS (и др.) нет
WRITE HOLE
- A, B, A xor B
- Меняем блок B ⇒ пишем B1 и A xor B1
- B1 записалось, A xor B1 нет
- Питание сдохло
- Отвалился диск A
- _, B1, A xor B
- Вместо A получим (A xor B xor B1)


Как с этим бороться?
Спросите архитекторов СХД
Если не ответят... 🤭
А медленно-то почему?
Все мы привыкли, что софт быстрый,
а диск и сеть медленные
на примере Ceph доказали, что это не так
Ceph
- Сначала я думал, что медленный из-за Filestore
- Они сделали Bluestore
- Линейная запись ускорилась (2x)
- А случайная нет 🤪 особенно на SSD
- Потом — что из-за сети и primary-репликации
- Но нет, RTT 10G ~ 0.03-0.05 мс
- Потом — что из-за fsync
- ОК, взяли SSD с конденсаторами
- ???
Загрузка CPU и RAM Ceph
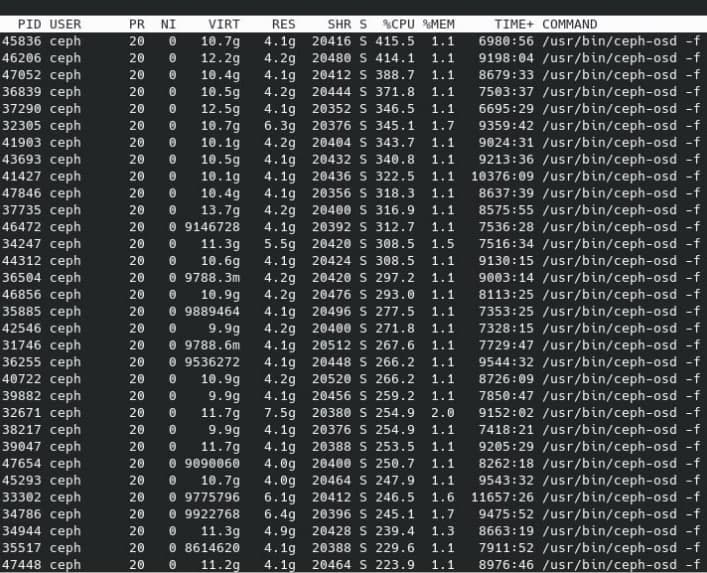
Software is becoming the bottleneck
Software is becoming the bottleneck
Наш г@8нокод заметили!!!!!1111
На самом деле это очень обидно
- Покупаешь ЛЮБОЕ железо 🚀
- Получаешь в Ceph 1000 iops 🐌 (Q=1)
- Пример от Micron
4 * (2*2*100 GbE + 2*24c Xeon 8168 + 10*Micron 9300 MAX)
1470 r + 630 w iops Q1
477000 w iops Q32 100 клиентами
Но ... ОДИН диск 9300 MAX может 310000 iops
-
Накладные расходы = 1 - = 92.3% 🤦477k40*310k/2
Можно ли исправить Ceph?

1 млн строк кода.
Можно. Но состаришься раньше.
Гораздо легче написать с нуля! 🤠
Цели разработки Vitastor
- Производительность
- Консистентность
- Для начала — только блочный доступ
- Для начала — только SSD или SSD+HDD
Простота
- Не делать 10 слоёв абстракций
- Не брать внешние фреймворки
- Не использовать многопоточность
- Не извращаться: ❌ DPDK/SPDK❌ модули ядра❌ copy-on-write FS❌ свой алгоритм консенсуса❌ Rust 🤣🤔 хотя... в будущем...
Чтобы не вышло, как всегда

Чтобы не вышло, как всегда

Что получилось
- ~30k строк кода
- C++, node.js, etcd
- ✅ Потребление CPU
0⟶стремится
- ✅ RAM ~ 512M на 1T (SSD)
- ✅ RAM ~ 16M на 1T (HDD, 4M блок)
- ✅ Latency от ~ 0.1 мс с RDMA
- ✅ Умеет все основные фичи Ceph RBD
- Тоже OSD, дерево размещения, PG, Pool
Симметричная распределённая архитектура

Дерево OSD |
|||||||
Rack 1
|
Rack 2
|
... | |||||
Дерево OSD + теги |
|||||||
Rack 1
|
Rack 2
|
... | |||||
Дерево OSD + теги + 2 OSD на NVMe |
|||||||
Rack 1
|
Rack 2
|
... | |||||
Pool, PG (placement group)
|
Pool 1
Erasure Code 2+1, tags = nvme, failure domain = host
|
Pool 2
2x репликация, hdd
|
||||||||||||||
|
|
* — первичный OSD
Две схемы избыточности
- Репликация
- N копий
- Копии в разных доменах отказа
- Erasure Code / коды коррекции ошибок
- N дисков данных + K дисков чётности
- Накладные расходы = (N+K)/N
- K=1 — «RAID 5», K=2 — «RAID 6»
- Дополнительные RTT при записи (иначе write hole!)
- Если живых OSD < pg_minsize, PG не стартует
А также (0.6.4)
- Снапшоты и CoW-клоны
- QEMU драйвер
- NBD для монтирования ядром
- Network Block Device, но по факту BlockDev in UserSpace
- CSI плагин для Kubernetes
Из интересного
- Оптимизация PG через сведение к ЛП
- Сумма PG → max
- Сумма PG по OSDi ≤ размер OSDi
- Режим ленивого fsync
- fsync медленный на настольных SSD
- Поддержка RDMA / RoCEv2
- Plug&Play, работает вместе с TCP, требует ≥ ConnectX-4
- «Плавный» сброс SSD-журнала на HDD
- Скорость записи ~ 1/свободное место в журнале


Тест № 1 — v0.4.0, сентябрь 2020
4 * (2*Xeon 6242 + 6*Intel D3-4510 + ConnectX-4 LX), 2x репликация
| Vitastor | Ceph | |
| T1Q1 randread | 6850 iops | 1750 iops |
| T1Q1 randwrite | 7100 iops | 1000 iops |
| T8Q64 randread | 895000 iops* | 480000 iops |
| T8Q64 randwrite | 162000 iops | 100000 iops |
| CPU на OSD | 3-4 CPU | 40 CPU |
* Должно быть вдвое больше. Не проверил, стенда больше нет
Тест № 2 — v0.4.0, сентябрь 2020
Тот же стенд, EC 2+1
| Vitastor | Ceph | |
| T1Q1 randread | 6200 iops | 1500 iops |
| T1Q1 randwrite | 2800 iops | 730 iops |
| T8Q64 randread | 812000 iops* | 278000 iops |
| T8Q64 randwrite | 85500 iops | 45300 iops |
| CPU на OSD | 3-5 CPU | 40 CPU |
* То же самое, должно быть больше. Спишем на v0.4.0 🤫
Тест № 3 — v0.5.6, март 2021
3 * (2*Xeon E5-2690v3 + 3*Intel D3-4510 + Intel X520-DA2), 2x репликация
| Vitastor | Ceph | |
| T1Q1 randread | 5800 iops | 1600 iops |
| T1Q1 randwrite | 5600 iops | 900 iops |
| T8Q128 randread | 520000 iops | 250000 iops* |
| T8Q128 randwrite | 74000 iops | 25000 iops |
| CPU на OSD | 5-7 CPU | 45 CPU |
| CPU на клиента | 90% | 300% |
* Слишком хорошо для Ceph, подозреваю, что бенчил кэш
Как попробовать?
- README.md#installation
- Взять bare-metal с SSD и ≥10G сетью
- Установить пакеты
- Запустить etcd
- Запустить mon
- Разметить & запустить OSD (по 1 на диск)
- Создать пул
- Либо залить образ и запустить QEMU
- Либо накатить YAML-ы CSI и создать PVC
Roadmap
- Сайт, документация
- Плагины к OpenNebula, OpenStack, Proxmox
- Web GUI и CLI
- Автоматизация установки
- iSCSI-прокси, псевдо-NFS
- Сжатие
- Scrub, контрольные суммы
- Cache tiering
- Поддержка NVDIMM / Optane DC
- ФС и S3 😈
Резюме
- У вас есть SSD и виртуалки или k8s?
- Пробуйте! → vitastor.io
- Помощь приветствуется:
- Код — плагины к OpenNebula и т.п.
- Обратная связь
- Тестовые стенды
Если облака хотят завоевать мир, им нужен Vitastor 🤩
Credits
- Спасибо участникам @ceph_ru и @vitastor
- В частности, ЦОД contell.ru
Можете арендовать там немного серверов :)

Контакты
- Виталий Филиппов
- vitastor.io
 t.me/vitastor
t.me/vitastor- vitalif@yourcmc.ru
- +7 (926) 589-84-07