
or How I wrote my own storage
Vitaliy Filippov
Vitastor
- vitastor.io
- Fast distributed SDS 🚀
- Latency from ~0.1 ms
- Architecturally similar to Ceph RBD
- Block access (VM / container disks)
- Symmetric clustering
- Ø SPOF
- Native QEMU driver
- Simple (no DPDK, etc)
- My own project written from scratch
What is performance?
- Q=1
- Best possible latency
- Not all applications can do Q=128 (DBMS...)
- Historically 'fixed' by RAID caches
- 4k write on SSD — 0.04 ms
- Ceph 4k write from ~ 1 ms — 2400 % overhead !
- Internal SDS of public clouds – ± the same
How to humiliate a network drive
Test method:
- Get an "SSD" drive
- Fill it
- Flush cache
- fio -name=test
-ioengine=libaio
-direct=1
-filename=/dev/sd..
-bs=4k
-iodepth=1 - -rw=randwrite
-fsync=1 - -rw=randread

iops: more is better
Apples to Apples
Test method:
- Get an "SSD" drive
- Fill it
- Flush cache
- fio -name=test
-ioengine=libaio
-direct=1
-filename=/dev/sd..
-bs=4k
-iodepth=1 - -rw=randwrite
-fsync=1 - -rw=randread

iops: more is better
Nah, let's humiliate everyone
Test method:
- Get an "SSD" drive
- Fill it
- Flush cache
- fio -name=test
-ioengine=libaio
-direct=1
-filename=/dev/sd..
-bs=4k
-iodepth=1 - -rw=randwrite
-fsync=1 - -rw=randread
iops: more is better
So it's not just an SDS
It's f*cked-up skunk, class A! (c)
The Beginning
I had 4 HDDs: 2+2+3+3 TB

Thin RAID 5
- Make RAID 5 from different size drives
- Don't lose space
- Don't do resync
- Possible?
Disk 1 111422333
Disk 2 114222333
Disk 3 111222
Disk 4 333214 - But nothing can do it (even now in 2021)
- ...except SDS systems!
Software-Defined Storage
Software that assembles usual servers with usual drives into a single scalable fault-tolerant storage cluster with extended features
Who uses SDS?

...and a lot more people, not for nothing Ceph chat has 1600+ members
Are there really no good SDS's?

Nothing to wear

Nothing to wear
Existing storage systems...
- Either lose data
- Either are slow
- Either are paid
- Or 1, 2, 3 in combinations


How can it be?
-
 *FS are more object storage than FS
*FS are more object storage than FS
-
 vSAN feels ok, S2D is SMB-based but rumored too
vSAN feels ok, S2D is SMB-based but rumored too
 Weka.io, OpenEBS, StorageOS, Intel DAOS
Weka.io, OpenEBS, StorageOS, Intel DAOS
↑ mysterious creatures- Yes, Minio may lose data too
- Storpool QEMU driver was just my imagination
- Ceph, Seaweed, Linstor can be trusted
What's the problem?
'RAID over Network'
Algorithms? What algorithms?
Just write to 3 places, simple & fast
not exactly
Surprises
- Data doesn't reach media without fsync
- Disk writes aren't atomic
- RAID 5 WRITE HOLE
- Metadata also has to be stored somewhere
- FS over FS leads to problems
- You already know?
- Authors of MooseFS (and etc.) don't
WRITE HOLE
- A, B, A xor B
- Change block B ⇒ write B1 and A xor B1
- B1 is written, A xor B1 isn't
- Power goes out
- Disk A dies
- _, B1, A xor B
- We get (A xor B xor B1) instead of A


How to fix it?
Ask storage architects
If they don't know... 🤭
Ok, and why are SDS's slow?
We're all used to the fact that software is fast
and disks and network are slow
proved, by example of Ceph, that it's not true
Ceph
- First I thought it was Filestore to blame
- They made Bluestore
- Linear writes became 2x faster
- Random I/O, especially on SSDs, didn't improve 🤪
- Then I thought about the primary-replication
- Also not true, 10G RTT is ~ 0.03-0.05 ms
- Then fsync
- OK, we bought SSDs with capacitors
- ???
Ceph CPU & RAM load
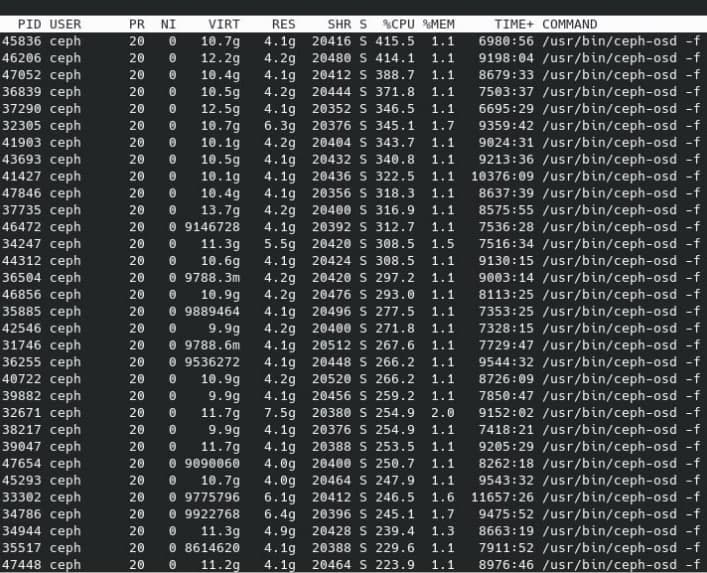
Software is becoming the bottleneck
Software is becoming the bottleneck
Our sh!7code has been noticed!!!!!1111
It's really frustrating
- Buy ANY hardware 🚀
- Get 1000 Q1 iops with Ceph 🐌
- Micron example
4 * (2*2*100 GbE + 2*24c Xeon 8168 + 10*Micron 9300 MAX)
1470 r + 630 w iops Q1
477000 w iops Q32 100 clients
But ... ONE Micron 9300 MAX drive can push 310000 iops
-
Overhead = 1 - = 92.3% 🤦477k40*310k/2
Can you fix Ceph?

1 million lines of code.
Yes you can. But it'll take years until you retire.
Writing from scratch is much easier! 🤠
Vitastor development goals
- Performance
- Consistency
- For now — block access only
- For now — SSD or SSD+HDD only
Simplicity
- No 10 layers of abstractions
- No external frameworks
- No multi-threading and locks
- No perversions: ❌ DPDK/SPDK❌ kernel modules❌ copy-on-write FS❌ own consensus algorithm❌ Rust 🤣🤔 maybe in the future...
Not be like

Not be like

The result
- ~30k lines of code
- C++, node.js, etcd
- ✅ CPU load
0⟶converges
- ✅ RAM ~ 512M for 1T (SSD)
- ✅ RAM ~ 16M for 1T (HDD, 4M block)
- ✅ Latency from ~ 0.1 ms with RDMA
- ✅ Supports all basic features of Ceph RBD
- Also has OSDs, placement tree, PGs, Pools
Symmetric clustering

OSD tree |
|||||||
Rack 1
|
Rack 2
|
... | |||||
OSD tree + tags |
|||||||
Rack 1
|
Rack 2
|
... | |||||
OSD tags + tags + 2 OSD per NVMe |
|||||||
Rack 1
|
Rack 2
|
... | |||||
Pools, PGs (placement groups)
|
Pool 1
Erasure Code 2+1, tags = nvme, failure domain = host
|
Pool 2
2x replication, hdd
|
||||||||||||||
|
|
* — primary OSD
Two redundancy schemes
- Replication
- N-wise
- Copies in different failure domains
- Erasure Codes
- N data + K parity disks
- Storage overhead = (N+K)/N
- K=1 — «RAID 5», K=2 — «RAID 6»
- Additional RTTs during writes (to close write hole!)
- PGs don't start if < pg_minsize OSDs are alive
More 'basic features'... (0.6.4)
- Snapshots and CoW clones
- QEMU driver
- NBD for kernel mounts
- Network Block Device, but works like BlockDev in UserSpace
- CSI plugin for Kubernetes
Non-trivial solutions
- PG optimisation using LP solver
- PG space total → max
- PG space per OSDi ≤ OSDi size
- Lazy fsync mode
- fsync is slow with desktop SSDs
- RDMA / RoCEv2 support
- Plug&Play, works along TCP, requires ≥ ConnectX-4
- «Smooth» flushing of SSD journal to HDD
- Write speed ~ 1/free journal space


Benchmark № 1 — v0.4.0, september 2020
4 * (2*Xeon 6242 + 6*Intel D3-4510 + ConnectX-4 LX), 2 replicas
| Vitastor | Ceph | |
| T1Q1 randread | 6850 iops | 1750 iops |
| T1Q1 randwrite | 7100 iops | 1000 iops |
| T8Q64 randread | 895000 iops* | 480000 iops |
| T8Q64 randwrite | 162000 iops | 100000 iops |
| CPU per OSD | 3-4 CPU | 40 CPU |
* Should have been 2 times more. Didn't investigate why
Benchmark № 2 — v0.4.0, september 2020
Same test rig, EC 2+1
| Vitastor | Ceph | |
| T1Q1 randread | 6200 iops | 1500 iops |
| T1Q1 randwrite | 2800 iops | 730 iops |
| T8Q64 randread | 812000 iops* | 278000 iops |
| T8Q64 randwrite | 85500 iops | 45300 iops |
| CPU per OSD | 3-5 CPU | 40 CPU |
* Same, should've been 2x more. Let's assume it was just v0.4.0 🤫
Benchmark № 3 — v0.5.6, march 2021
3 * (2*Xeon E5-2690v3 + 3*Intel D3-4510 + Intel X520-DA2), 2 replicas
| Vitastor | Ceph | |
| T1Q1 randread | 5800 iops | 1600 iops |
| T1Q1 randwrite | 5600 iops | 900 iops |
| T8Q128 randread | 520000 iops | 250000 iops* |
| T8Q128 randwrite | 74000 iops | 25000 iops |
| CPU per OSD | 5-7 CPU | 45 CPU |
| CPU per client | 90% | 300% |
* Too good for Ceph, I suspect I was benchmarking cache
How to try it out
- README.md#installation
- Get baremetal servers with SSDs and ≥10G net
- Install packages
- Start etcd
- Start mon
- Create & start OSDs (1 per drive)
- Create a pool
- Either upload an image and run QEMU
- Or apply CSI YAMLs and create a PVC
Roadmap
- Site, documentation
- OpenNebula, OpenStack, Proxmox plugins
- Web GUI and CLI
- Automated deployment
- iSCSI proxy and/or pseudo-NFS
- Compression
- Scrub, checksums
- Cache tiering
- NVDIMM / Optane DC support
- FS and S3 😈
Summary
- Do you have SSDs and VMs or k8s?
- Start here! → vitastor.io
- Help is appreciated:
- Code — plugins for OpenNebula & etc
- Feedback
- Test rigs
If clouds want to conquer the world, they need Vitastor 🤩
Credits
- Thanks to @ceph_ru and @vitastor members
- Including contell.ru datacenter
Go and rent some of their servers if you want :)

Contacts
- Vitaliy Filippov
- vitastor.io
 t.me/vitastor
t.me/vitastor- vitalif@yourcmc.ru
- +7 (926) 589-84-07